데이터 모델링의 다양한 관계 패턴, 그 중에서도 부모-자식 관계 설계에 대하여
데이터베이스 설계에서 테이블 간의 관계를 어떻게 구성하느냐는 애플리케이션의 성능, 확장성, 그리고 유지보수성에 결정적인 영향을 미칩니다. 프로젝트에서 부모-자식 관계를 설계하며 경험한 교훈을 공유합니다.
데이터 모델링에서의 다양한 관계 패턴
데이터 모델링에서 주로 사용되는 관계 패턴은 다음과 같습니다:
1. 일대다(One-to-Many) 관계
가장 흔한 관계 유형으로, 하나의 레코드가 여러 개의 다른 레코드와 연관됩니다.
예시: 사용자(1)와 그 사용자가 작성한 게시글(N)
// TypeORM 예시
@Entity()
class User {
@OneToMany(() => Post, post => post.author)
posts: Post[];
}
@Entity()
class Post {
@ManyToOne(() => User, user => user.posts)
author: User;
}
2. 다대다(Many-to-Many) 관계
여러 레코드가 다른 테이블의 여러 레코드와 연관되는 관계입니다.
예시: 학생과 수강하는 과목
// TypeORM 예시
@Entity()
class Student {
@ManyToMany(() => Course)
@JoinTable()
courses: Course[];
}
@Entity()
class Course {
@ManyToMany(() => Student)
students: Student[];
}
3. 일대일(One-to-One) 관계
하나의 레코드가 다른 테이블의 딱 하나의 레코드와만 연관됩니다.
예시: 사용자와 프로필
// TypeORM 예시
@Entity()
class User {
@OneToOne(() => Profile)
@JoinColumn()
profile: Profile;
}
@Entity()
class Profile {
@OneToOne(() => User)
user: User;
}
4. 자기 참조(Self-Referencing) 관계
같은 테이블 내에서 레코드 간에 관계가 형성되는 패턴입니다.
예시: 조직도에서 관리자와 부하 직원 관계
// TypeORM 예시
@Entity()
class Employee {
@ManyToOne(() => Employee, employee => employee.subordinates)
manager: Employee;
@OneToMany(() => Employee, employee => employee.manager)
subordinates: Employee[];
}
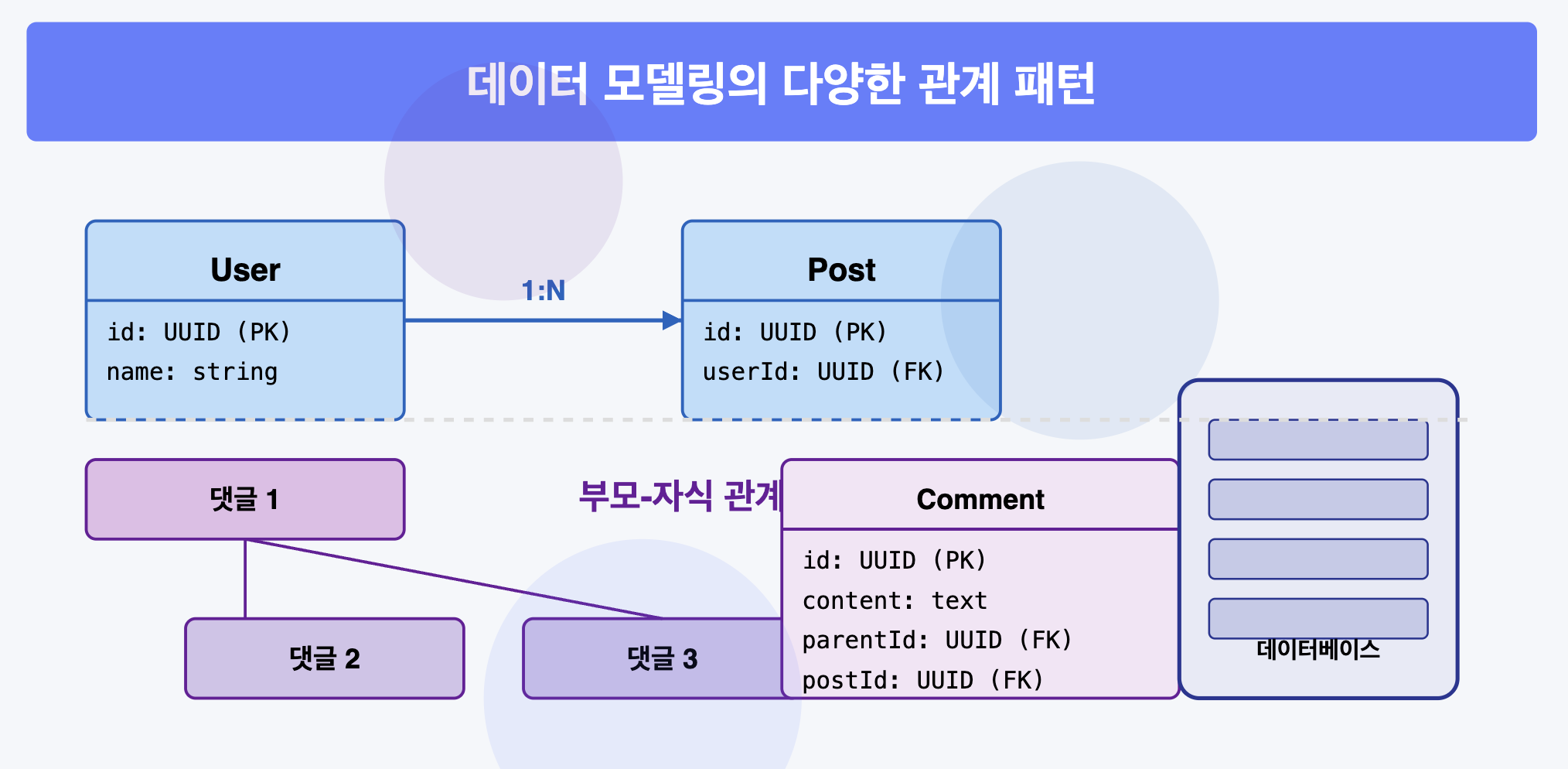
5. 부모-자식(Parent-Child) 관계
계층적 데이터 구조를 표현하는 관계로, 자기 참조의 특별한 형태입니다.
일대다 관계에서도 부모엔티티, 자식엔티티 이런 말을 썼었는데 이때의 부모-자식과는 조금 다릅니다.
- 일대다 관계: 서로 다른 엔티티 간의 관계를 설명합니다.
- 부모-자식 관계: 주로 계층적 데이터를 설명하거나 동일 엔티티 내 자기 참조 관계를 나타냅니다.
부모-자식 관계
부모-자식 관계는 언제 쓰일까요?
부모-자식 관계는 다양한 시나리오에서 활용될 수 있습니다:
- 조직도 구조
- 카테고리와 하위 카테고리
- 댓글과 대댓글
- 파일 시스템의 폴더 구조
- 게시글과 수정 이력
- 문서 버전 관리
부모-자식 관계를 설계하는 방법
부모-자식 관계를 설계할 때는 크게 두 가지 접근 방식이 있습니다:
- 자식이 부모를 참조하는 방식
- 자식 엔티티에 부모 ID를 외래 키로 저장
- 가장 일반적이고 직관적인 방식
- 부모가 자식들을 참조하는 방식
- 부모 엔티티에 자식 ID 목록을 저장
- 관계형 DB에서는 보통 중간 테이블이 필요하고, NoSQL에서는 배열로 저장
두 접근법 중에서 대부분의 경우 자식이 부모를 참조하는 방식이 더 효과적입니다.
그렇게 느낀 이유를 예시와 함께 설명하겠습니다.
예시: 댓글 시스템에서의 부모-자식 관계
소셜 미디어 플랫폼에서 댓글과 대댓글(답글) 기능을 개발 중이라고 가정합시다.
요구사항은 단순히 댓글을 나열하는 것이 아니라, 대댓글이 원래 댓글 아래에 계층적으로 표시되어야 하는 것이며 이 구조가 무한히 깊어질 수 있다는 것입니다.
해결 접근법: 부모-자식 관계 모델링
이 문제를 해결하기 위해서는 몇 가지 방법이 있을 수 있습니다.
- 평면적 접근법: 모든 댓글에 부모 댓글 ID 필드 추가
댓글 테이블 - id: 1, content: "좋은 글이네요", parent_id: NULL (최상위 댓글) - id: 2, content: "저도 동의합니다", parent_id: 1 (1번 댓글에 대한 답글) - id: 3, content: "감사합니다", parent_id: 2 (2번 댓글에 대한 답글)- 장점: 구현 간단, 직접적인 부모-자식 관계 표현
- 단점: 깊은 중첩 구조 조회 시 여러 번의 쿼리 필요
- 경로 열거 접근법: 각 댓글에 전체 경로 저장 (예: “1/5/12”)
댓글 테이블 - id: 1, content: "좋은 글이네요", path: "1" (최상위 댓글) - id: 2, content: "저도 동의합니다", path: "1/2" (1번 댓글의 답글) - id: 3, content: "감사합니다", path: "1/2/3" (2번 댓글의 답글)- 장점: 전체 계층 구조를 한 번의 쿼리로 조회 가능
- 단점: 경로 문자열 처리 복잡, 부모 이동 시 모든 자식 경로 업데이트 필요
- 중첩 집합 모델(Nested Set Model): 왼쪽/오른쪽 값으로 계층 표현
댓글 테이블 - id: 1, content: "좋은 글이네요", left: 1, right: 6 (최상위 댓글) - id: 2, content: "저도 동의합니다", left: 2, right: 5 (1번의 자식) - id: 3, content: "감사합니다", left: 3, right: 4 (2번의 자식)- 장점: 전체 트리 검색 효율적, 조상/자손 쿼리 빠름
- 단점: 구현 복잡, 삽입/삭제 시 많은 레코드 업데이트 필요
이 중에서 저는 평면적 접근법(자식이 부모를 참조)을 선택했습니다.
이유는 실제 사용 패턴에서 2단계 이상의 중첩 댓글을 거의 작성하지 않는다는 점에서, 성능과 복잡성의 균형에서 단순성을 선택했기 때문입니다.
물론 향후 더 복잡한 계층 구조가 필요하면 다른 접근법으로 쉽게 마이그레이션할 수 있는 구조이기도 했습니다.
이 데이터를 표현할 때, 자식이 부모 ID를 갖는 게 맞을까 부모가 자식 ID를 갖는 게 맞을까 고민을 했었고, 그 고민 속에서 배운 점을 서술하기 위해 기나긴 서론을 작성했네요.
처음엔 자식이 부모 ID를 갖게 하고 싶었습니다. 이유는, 필터링이 쉬울 것 같아서..!
사실 기본적인 댓글들이야 그냥 나열해도 되지만, 특별한 처리가 필요한 건 자식들이니까요.
그렇게 생각하고 작업을 하던 도중 뭔가 이상한 낌새를 느끼고, 갈팡질팡하고 있던 찰나

을 얻게 됩니다.
자식이 부모를 참조해야 하는 이유
는 다음과 같습니다.
- 일대다 관계의 자연스러운 표현
- 한 부모에 여러 자식이 존재할 수 있지만, 자식은 하나의 부모만 가짐
- 이는 데이터베이스의 외래 키 제약조건과 자연스럽게 맞음
- 레코드 속성 판단
- 자식이 부모를 참조할 때: 부모 ID가 있으면 자식, 없으면 부모
- 부모가 자식을 참조할 때: 자식 목록이 비어 있어도 부모일 수 있어서 판단 모호
- 데이터 일관성
- 자식이 부모를 참조하면 부모 삭제 시 무결성 제약조건으로 처리 가능
- 부모가 자식들을 참조하면 부모 삭제 시 자식 ID 목록의 유효성 검증 필요
결론
결론은 사실 자식이 부모를 참조해야 하는 이유만 잘 알아두시면, 나중에 저처럼 갈팡질팡 안 하실 거라는 이야기!
읽어보니 꽤나 당연한 소리같죠? 그렇지만 언젠가 떠오를 때가 있으실 겁니다. (그러길,,)
여기까지. 안녕!