장애를 검출하는 방법, 헬스체크: Service Monitoring, Health Check
서비스 장애시의 대응을 알기 이전에, ^장애^란 어떻게 발견될 수 있을까요?
서비스 모니터링의 가장 기본이 되는 헬스체크에 대해서 이야기 합니다.
AWS가 대신 해줘서 몰랐을, Application Layer에서의 Health Check 외의, 다른 계층에서의 Health Check도 알아 보아요.
- Layer 3: ICMP로 시작하는 기본적인 연결 확인
- Layer 4: TCP/UDP 포트 모니터링
- Layer 7: 실제 서비스 수준의 모니터링
- 다층적 모니터링의 중요성
- AWS와 각 네트워크 계층
- AWS와 헬스체크 자동화의 이점
- 구체적으로 들어보는 예시: AWS ECS와 NestJS에서의 헬스체크
- 헬스체크 주의사항: 자주 하는 실수들
- 추천하는 헬스체크 패턴
- 마치며
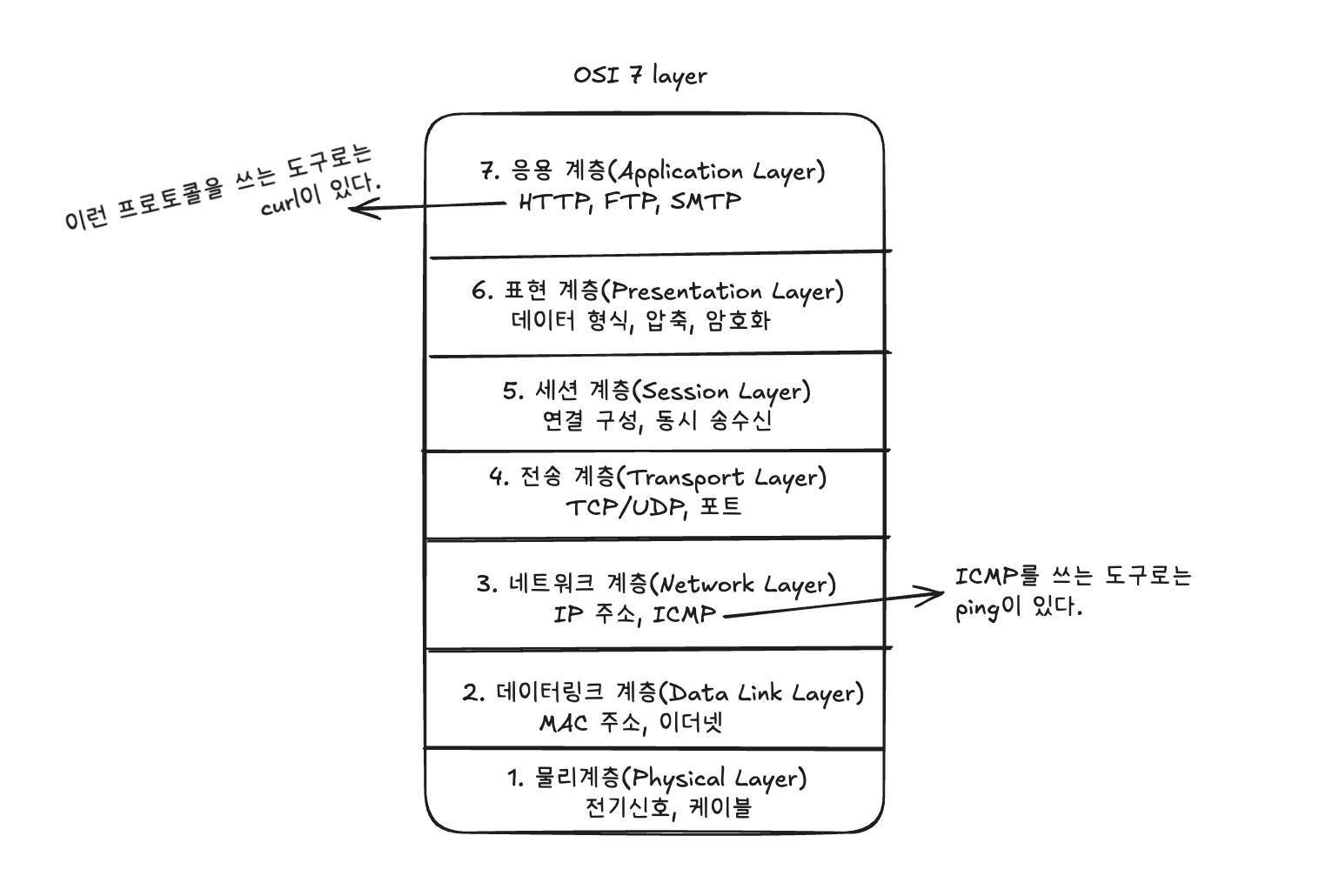
우선 OSI 7계층은 이렇게 생겼습니다. 대부분의 헬스체크 도구들은 3, 4, 7 계층을 중심으로 구현되어 있어요.
ICMP(Layer 3, 네트워크 계층)로 “서버가 살아는 있는가?”를 확인하고,
포트(Layer 4, 전송 계층) 체크로 “웹 서버가 떠 있기는 한가?” 확인하고,
HTTP(Layer 7, 응용 계층) 요청으로 “웹 서버가 제대로 동작하나?” 확인할 수 있거든요.
Layer 3: ICMP로 시작하는 기본적인 연결 확인
ICMP(Internet Control Message Protocol)는 네트워크 계층에서 동작하는 가장 기본적인 프로토콜입니다.
우리가 흔히 사용하는 ping* 명령어가 바로 이 ICMP를 사용해요.
ICMP 모니터링을 통해서는 기본적인 네트워크 연결성을 확인합니다.
🧐 네트워크 연결이 끊기는 경우는 어떤 경우인가요?
- 물리적 단절: 네트워크 케이블이 끊어짐, 서버 전원이 꺼짐, 라우터/스위치 고장
- 네트워크 설정 문제: IP 설정 오류, 라우팅 테이블 문제
- 네트워크 과부하: 네트워크 혼잡으로 패킷(IP에서의 데이터 최소단위 묶음) 손실, DDoS 공격으로 인한 응답 불가
*ping: ICMP 프로토콜의 메시지 타입 중 하인 Echo의 Request와 Reply를 보내고 받는 도구입니다. echo 메시지를 사용해서 구현된 유틸리티라고 할 수 있어요.
ICMP로 할 수 있는 것과, 할 수 없는 것
ICMP는
- 라우터의 헬스체크에 적합합니다.
- 라우터가 확실히 패킷을 전송할 수 있는지 확인하거든요.
- 기본적인 네트워크 연결성 확인이 가능합니다.
- 네트워크 레이턴시 모니터링에 유용합니다.
그러나,
- 웹 서비스가 다운된 경우 감지할 수 없습니다.
- 서버 자체는 켜져 있고, 네트워크도 연결되어 있으나 웹 서버 프로세스가 죽어 있는 경우. curl로는 연결에 실패하지만, ping으로는 성공할 수 있습니다.
- 많은 조직에서 보안상의 이유로 ICMP를 차단하기도 합니다.
네트워크 연결이 끊기지 않았는데도 ping이 안되는 다음과 같은 경우도 있습니다.
- 방화벽에서 ICMP를 차단했을 때
- 서버가 ICMP 응답을 비활성화했을 때
- 네트워크는 정상이지만 해당 호스트만 문제가 있을 때
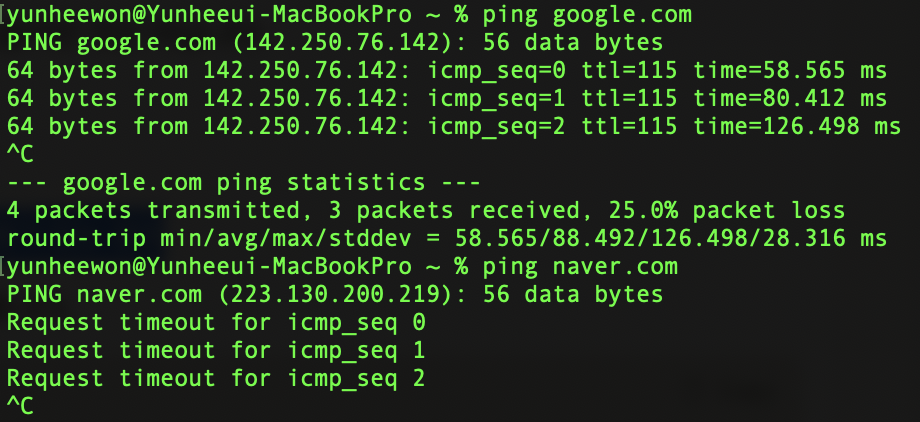 네이버는 ICMP 응답을 비활성화했네요.
네이버는 ICMP 응답을 비활성화했네요.
ICMP를 차단하는 이유
보안 관점에서 ICMP를 차단하는 것은 꽤 일반적인 관행이라고 합니다. 그 이유는:
- 서버 존재 여부 은폐
- DDoS 공격 방지
- 네트워크 구조 노출 방지
를 위해서예요.
예를 들어, traceroute 명령을 사용하면 패킷이 목적지까지 가는 경로의 모든 라우터가 노출됩니다. 이는 공격자에게 네트워크의 구조를 파악할 수 있는 정보를 제공할 수 있겠죠. 혹은 내부 네트워크의 IP 대역이라거나.
공격자는 이 정보를 통해
- 네트워크의 병목 지점을 파악해 DDoS 공격을 할 수도 있고,
- ICMP 응답의 TTL 값이나 TCP Window Size등을 분석해 라우터를 파악한 뒤 취약점을 찾아 공격할 수도 있답니다.
쿠팡의 traceroute 결과를 한 번 봐볼까요?
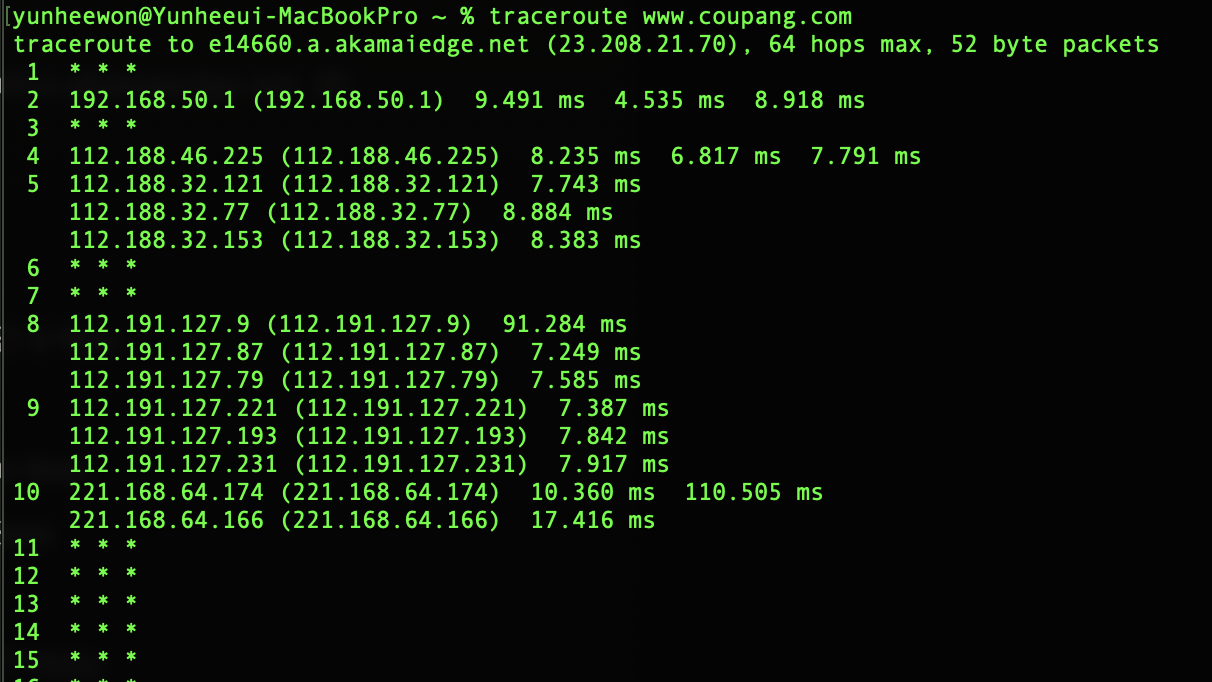
목적지는 Akamai*CDN 서버네요. 말고는 딱히 유의미한 정보가 보이지 않네요.
공유기가 KT라서 KT 네트워크로 라우팅된다는 것 밖엔..!
Akamai:는 CDN 사업의 선두주자, 였던 곳으로 아직까지도 CloudFlare, CloudFront(AWS)와 함께 CDN의 Top 3 점유율을 가지고 있습니다.
+112.{188|191|216}.xxx.xxx 는 대부분 KT, {219|125}.xxx.xxx.xxx는 대부분 SKT, {211|106}.xxx.xxx.xxx는 대부분 LG라네요. 정확한 IP 대역 소유자는 KRNIC이나, WHOIS를 찾아보면 되겠습니다 😉
Layer 4: TCP/UDP 포트 모니터링
포트 모니터링은 전송 계층에서 이루어지는 헬스체크입니다.
TCP로 접속 테스트를 수행하여 특정 포트가 열려있는지 확인할 수 있어요.
TCP 포트란?
포트는 하나의 IP 주소에서 여러 네트워크 프로그램을 구분하기 위한 논리적인 번호입니다.
0부터 65535까지의 번호를 사용할 수 있으며, 각 포트는 특정 서비스와 연결됩니다.
포트 번호는 다음과 같이 분류됩니다:
- Well-known 포트 (0-1023)
- 20, 21: FTP (파일 전송)
- 22: SSH (원격 접속)
- 23: Telnet
- 25: SMTP (이메일 전송)
- 53: DNS
- 80: HTTP
- 443: HTTPS
- Registered 포트 (1024-49151)
- 1433: MS-SQL
- 3306: MySQL
- 5432: PostgreSQL
- 6379: Redis
- 8080: 대체 HTTP 포트
- 27017: MongoDB 등
- Dynamic/Private 포트 (49152-65535)
- 임시 또는 개인적인 용도로 사용
웹 서버는 어떤 포트든 사용할 수 있지만, 80과 443을 기본으로 사용합니다. 그 이유는:
- 브라우저가 기본적으로 이 포트들을 사용
- 방화벽에서 기본적으로 허용되는 경우가 많음
- URL에서 포트 번호를 생략 가능 https://oneune.github.io = https://oneune.github.io:443
UDP 포트는?
반면 같은 번호여도, 다른 포트인 UDP 포트가 있습니다.
TCP와 UDP는 각각의 특성에 따라 다른 용도로 사용됩니다.
TCP (Transmission Control Protocol)
- 연결 지향적
- 데이터 전달과 순서 보장
- 신뢰성이 필요한 데이터에 사용
- 예: 웹 브라우징, 파일 전송, 이메일
UDP (User Datagram Protocol)
- 비연결형
- 데이터 전달/순서 보장 없음
- 빠른 전송이 필요한 경우에 사용
- 예: DNS 쿼리, 실시간 스트리밍, 게임
게임 서버같은 경우:
- TCP: 채팅, 계정 정보 등 정확성이 중요한 데이터
- UDP: 캐릭터 위치, 실시간 전투 등 빠른 전송이 중요한 데이터
이런식으로 사용됩니다.
좀 더 친근한 예시를 확인하려면 Discord Establishing a Voice UDP Connection 이런 문서를 참고할 수 있겠네요.
주요 UDP 포트
- 53: DNS 쿼리
- 67, 68: DHCP
- 123: NTP (시간 동기화)
- 161: SNMP (네트워크 관리)
- 514: Syslog
포트 모니터링으로 할 수 있는 것과, 할 수 없는 것
포트 모니터링 시
- 웹 서비스 다운 상태를 감지 할 수 있습니다.
- 방화벽 규칙 검증에 유용합니다.
- 기본적인 서비스 가용성을 확인 할 수 있습니다.
그러나,
- 서버 과부하 상태를 감지할 수 없습니다.
- 애플리케이션 레벨의 에러 감지를 할 수 없습니다.
- 설정 파일에 오류가 있어서 요청을 제대로 처리 못한다거나
- DB 연결이 끊어져서 데이터를 못 가져온다거나 하는 류의 에러
Layer 7: 실제 서비스 수준의 모니터링
응용 계층에서는 실제 HTTP 요청을 보내 정상적인 응답이 오는지 확인합니다.
가장 실제 사용자의 경험과 유사한 모니터링 방식이에요.
응용 계층의 모니터링으로 할 수 있는 것과, 할 수 없는 것
응용 계층의 모니터링으로
- 실제 서비스 상태를 정확히 파악할 수 있습니다.
- 대부분의 서비스 이상을 감지할 수 있습니다.
- 응답 시간, 콘텐츠 정확성 등 세부적인 모니터링이 가능합니다.
응용 계층이 최종 단계의 모니터링이므로, 헬스체크의 관점에서 할 수 없는 것은 없습니다.
다만, 주의해야할 점들이 있어요.
- 응용 계층의 모니터링은 서버에 부하를 줄 수 있습니다. 그러므로 모니터링 주기와 타임아웃 설정에 주의가 필요합니다.
- APM(Application Performance Monitoring) 기능이 활성화된 New Relic이나 Datadog같은 걸 사용할 때는 특히 주의가 필요합니다.
응용 계층 모니터링이 서버에 어떻게 부하를 주나요?
1. 모니터링 요청 자체의 부하
- 추가적인 HTTP 요청 발생: 모니터링 도구가 서비스의 상태를 확인하기 위해 지속적으로 API 엔드포인트를 호출합니다. 이는 추가적인 트래픽을 발생시킵니다.
- 주기적인 요청: 예를 들어, 10초마다 상태 확인 요청을 보내는 경우, 하루에 8,640회의 추가 요청이 발생하게 됩니다.
// NestJS에서의 health check API 예시
@Get('/health')
async checkHealth() {
// 이 API가 호출될 때마다 서버 리소스를 사용합니다
return { status: 'ok' };
}
2. APM 도구의 오버헤드
- 코드 계측(Instrumentation): New Relic이나 Datadog 같은 APM 도구는 애플리케이션 코드에 추가적인 코드를 삽입하여 성능을 측정합니다.
- 메모리 사용 증가: APM 에이전트는 메트릭을 수집하고 저장하기 위해 추가 메모리를 사용합니다.
- CPU 사용 증가: 메트릭을 처리하고 전송하는 과정에서 CPU 리소스를 사용합니다.
// Next.js에서 Datadog APM 설정 예시
import { datadogRum } from '@datadog/browser-rum';
datadogRum.init({
applicationId: 'your-app-id',
clientToken: 'your-client-token',
site: 'datadoghq.com',
service: 'your-service-name',
env: 'production',
// 수집하는 데이터가 많을수록 오버헤드가 커집니다
trackInteractions: true,
trackResources: true,
trackLongTasks: true,
});
3. 복잡한 헬스체크의 부하
- 종속성 검사: 데이터베이스, 캐시, 외부 API 등 종속성을 확인하는 고급 헬스체크는 상당한 리소스를 소모할 수 있습니다.
- 심층 검사: 단순히 서비스가 살아있는지 확인하는 것이 아니라 기능이 제대로 작동하는지 확인하는 과정에서 비즈니스 로직 실행이 필요할 수 있습니다.
// NestJS에서 복잡한 헬스체크 예시
@Get('/deep-health')
async checkDeepHealth() {
// 데이터베이스 연결 확인
await this.databaseService.ping();
// Redis 캐시 확인
await this.redisService.ping();
// 외부 API 확인
await this.externalApiService.checkStatus();
// 이러한 모든 작업이 리소스를 소모합니다
return { status: 'ok' };
}
4. 로깅과 메트릭 수집의 부하
- 로그 생성: 모니터링 시스템은 많은 로그를 생성하며, 이를 처리하고 저장하는 과정에서 디스크 I/O와 CPU를 사용합니다.
- 메트릭 수집 및 전송: 수집된 메트릭을 외부 시스템으로 전송하는 과정에서 네트워크 대역폭을 사용합니다.
5. AWS 환경에서의 특별한 고려사항
- 컨테이너화된 환경: ECS나 EKS에서 실행되는 경우, 컨테이너 리소스 제한에 따라 모니터링 오버헤드가 서비스 성능에 더 큰 영향을 미칠 수 있습니다.
- 오토스케일링: 과도한 모니터링으로 인한 리소스 사용량 증가가 오토스케일링을 불필요하게 트리거할 수 있습니다.
이러한 부하를 최소화하기 위한 모범 사례:
- 적절한 모니터링 간격 설정 (너무 빈번하지 않게)
- 경량 헬스체크와 심층 헬스체크 구분하여 사용
- 샘플링 비율 조정 (모든 요청을 모니터링하지 않고 일부만)
- 프로덕션 환경과 유사한 환경에서 모니터링 오버헤드 테스트
다층적 모니터링의 중요성
각 계층의 헬스체크는 서로 다른 목적과 장단점을 가지고 있습니다. 실제 운영 환경에서는 이들을 조합해 사용하는 것이 일반적이에요.
근데 이제 클라우드를 쓴다면 일반적이지 않긴 합니다. 대신 해주니까..
- ICMP로 기본 네트워크 연결 확인
- 포트 체크로 서비스 포트 오픈 여부 확인
- HTTP 요청으로 실제 서비스 상태 확인
이러한 다층적 접근은 문제 발생 시 어느 계층에서 문제가 발생했는지 빠르게 파악할 수 있게 해줍니다.
AWS와 각 네트워크 계층
앞서 OSI 7계층과 헬스체크에 대해 이야기했는데, AWS의 다양한 서비스들도 이러한 네트워크 계층 개념을 기반으로 구축되어 있습니다. AWS 서비스들을 각 네트워크 계층별로 분류해보면 다음과 같습니다.
클라우드 환경에서는 앞서 설명한 Layer 3, 4 레벨의 모니터링을 직접 구현할 필요가 없는 경우가 많습니다.
클라우드가 자동으로 처리해주기 때문이죠. AWS가 각 계층의 모니터링을 어떻게 처리하는지 살펴볼까요?
Layer 3 (네트워크 계층) 모니터링
AWS에서 네트워크 계층 모니터링은 다음과 같은 서비스와 기능을 통해 이루어집니다.
- VPC Flow Logs: 네트워크 트래픽을 상세히 기록하여 통신 패턴과 보안 이슈 분석
- Route Tables: 네트워크 라우팅 상태 관리
- Network ACLs: IP 기반 접근 제어 관리
예를 들어, EC2 인스턴스나 ECS 컨테이너 간의 기본적인 네트워크 연결성은 VPC 인프라 레벨에서 자동으로 관리됩니다.
따라서 우리가 직접 ping을 통해 확인할 필요가 줄어듭니다.
Layer 4 (전송 계층) 모니터링
전송 계층에서는 다음과 같은 방식으로 모니터링이 이루어집니다.
- Security Groups: 포트 기반 접근 제어 관리
- Network Load Balancer(NLB): TCP/UDP 연결 상태 자동 체크
- AWS Shield: DDoS 공격 실시간 감지 및 방어
NLB의 Target Group 설정을 보면 Layer 4 수준의 헬스체크가 어떻게 구성되는지 알 수 있습니다.
{
"healthCheck": {
"protocol": "TCP", // Layer 4 체크
"port": 80,
"interval": 30,
"timeout": 10,
"unhealthyThreshold": 2,
"healthyThreshold": 3
}
}
이 설정은 단순히 대상 서버의 80번 포트가 열려있는지(TCP 연결이 가능한지)만 확인합니다.
애플리케이션 레벨의 상태는 확인하지 않습니다.
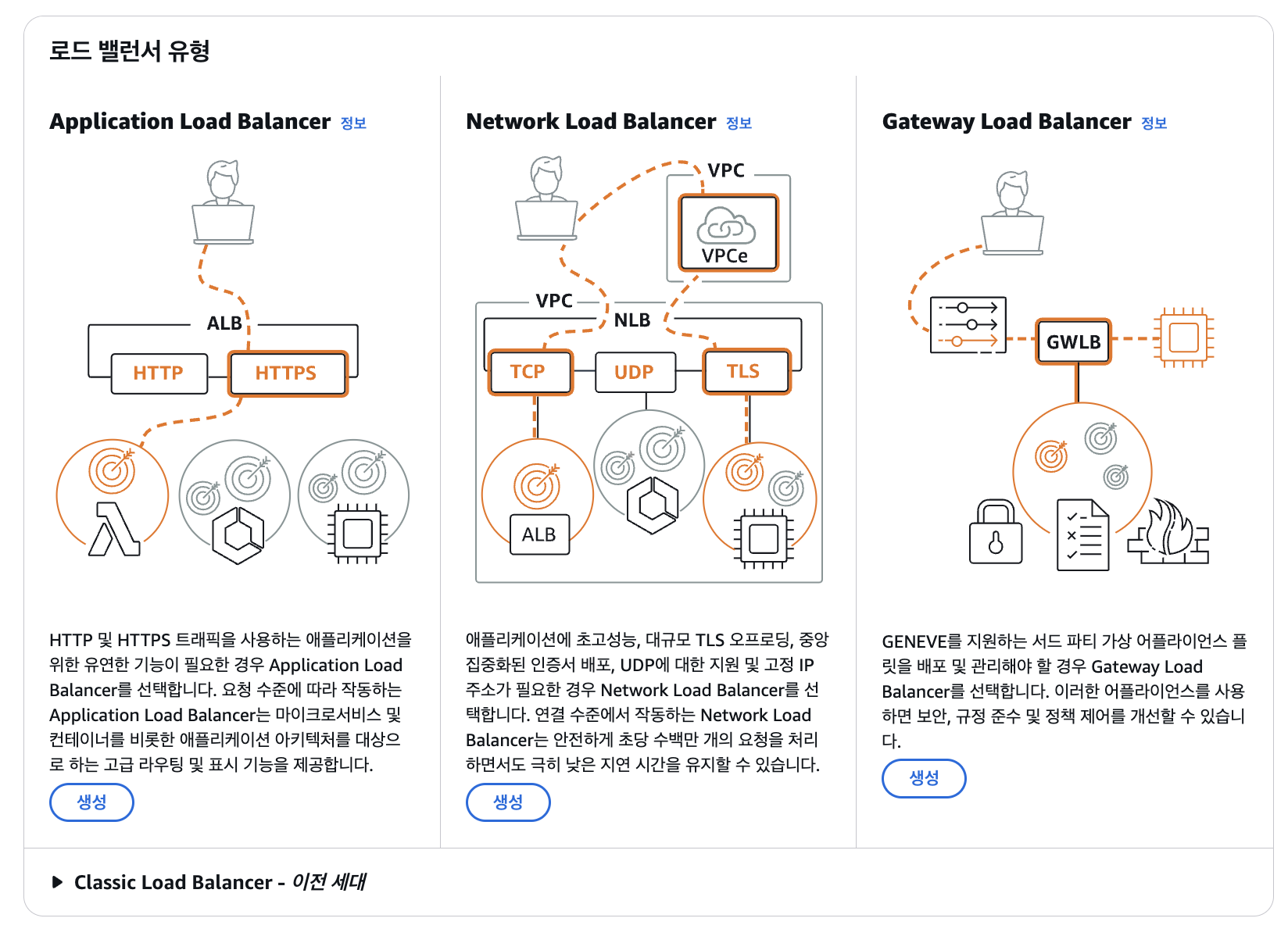 AWS는 위와 같은 유형의 로드밸런서가 존재합니다.
AWS는 위와 같은 유형의 로드밸런서가 존재합니다.
Layer 7 (응용 계층) 모니터링
응용 계층 모니터링은 Application Load Balancer(ALB)를 통해 주로 이루어집니다:
{
"healthCheck": {
"protocol": "HTTP",
"path": "/health",
"port": "traffic-port",
"interval": 30,
"timeout": 5,
"unhealthyThreshold": 2,
"healthyThreshold": 5,
"matcher": {
"httpCode": "200-299"
}
}
}
이 설정은 /health 엔드포인트에 HTTP 요청을 보내고 응답 코드가 200번대인지 확인합니다.
이는 앞서 설명한 Layer 7 헬스체크와 동일한 방식입니다.
AWS와 헬스체크 자동화의 이점
AWS 환경에서는 위와 같은 헬스체크 메커니즘이 자동화되어 있어 다음과 같은 이점이 있습니다.
- 자동 감지 및 복구
- 문제가 발생한 인스턴스나 컨테이너를 자동으로 감지
- Auto Scaling Group과 연계하여 비정상 인스턴스 교체
- ECS 서비스에서 비정상 컨테이너 자동 재시작
- 트래픽 관리 자동화
- ALB/NLB가 비정상 대상으로의 트래픽 자동 차단
- Route 53 헬스체크와 연계하여 DNS 라우팅 조정
- CloudFront가 오리진 서버 장애 시 대체 오리진으로 전환
- 모니터링 및 알림 통합
- CloudWatch와 연계하여 헬스체크 상태 모니터링
- EventBridge로 헬스체크 실패 시 자동화된 워크플로우 트리거
- SNS를 통한 알림 전송
AWS ECS 환경에서의 헬스체크와 자동 복구는 다음과 같이 여러 계층에서 병렬적으로 이루어집니다.
- 컨테이너 헬스체크
- Dockerfile의 HEALTHCHECK 지시문 또는 ECS Task Definition의 healthCheck 설정으로 컨테이너 자체의 상태를 모니터링합니다.
- 이 체크가 실패하면 ECS는 해당 컨테이너를 비정상으로 표시합니다.
- 로드밸런서 헬스체크
- 동시에, ALB/NLB의 Target Group 설정을 통해 독립적으로 컨테이너의 상태를 확인합니다.
- 이 체크가 실패하면 로드밸런서는 해당 타겟(컨테이너)으로의 트래픽을 중단합니다.
- 서비스 레벨 복구
- ECS 서비스는 컨테이너 헬스체크 결과에 따라 필요 시 태스크를 종료하고 새로운 태스크를 시작합니다.
- 이때 desiredCount 설정에 따라 서비스가 항상 지정된 수의 정상 태스크를 유지하도록 합니다.
- 로드밸런서 트래픽 조정
- 새 컨테이너가 시작되면, 로드밸런서는 자체 헬스체크를 수행하고 정상으로 판단되면 트래픽을 새 컨테이너로 보내기 시작합니다.
이런 자동화된 시스템 덕분에, 개발자는 인프라 수준의 헬스체크보다 애플리케이션 로직의 정상 작동 여부를 확인하는 데 더 집중할 수 있습니다.
구체적으로 들어보는 예시: AWS ECS와 NestJS에서의 헬스체크
AWS ECS
AWS ECS에서 헬스체크는 주로 두 가지 레벨에서 이루어집니다.
- 컨테이너 레벨 헬스체크
{ "healthCheck": { "command": ["CMD-SHELL", "curl -f http://localhost:3000/health || exit 1"], "interval": 30, "timeout": 5, "retries": 3, "startPeriod": 60 } }- ECS 컨테이너의 task definition에서 설정
- 실패 시 컨테이너 재시작
- startPeriod는 gracePeriod같은 것으로 컨테이너가 떠서 이 안에 healthCheck를 성공하면 healthy한 것으로 판단
- ALB(Application Load Balancer) 헬스체크
{ "healthCheckPath": "/health", "healthCheckIntervalSeconds": 30, "healthyThresholdCount": 3, "unhealthyThresholdCount": 2, "healthCheckTimeoutSeconds": 5 }- Target Group 레벨에서 설정
- 실패 시 해당 컨테이너로의 트래픽 차단
NestJS
NestJS에서는 @nestjs/terminus를 사용해 체계적인 헬스체크를 구현할 수 있습니다.
// health.module.ts
import { Module } from '@nestjs/common';
import { TerminusModule } from '@nestjs/terminus';
import { HttpModule } from '@nestjs/axios';
import { HealthController } from './health.controller';
@Module({
imports: [TerminusModule, HttpModule],
controllers: [HealthController],
})
export class HealthModule {}
// health.controller.ts
import { Controller, Get } from '@nestjs/common';
import {
HealthCheck,
HealthCheckService,
TypeOrmHealthIndicator,
MemoryHealthIndicator,
DiskHealthIndicator,
} from '@nestjs/terminus';
@Controller('health')
export class HealthController {
constructor(
private health: HealthCheckService,
private db: TypeOrmHealthIndicator,
private memory: MemoryHealthIndicator,
private disk: DiskHealthIndicator,
) {}
@Get()
@HealthCheck()
check() {
return this.health.check([
// DB 연결 상태 체크
() => this.db.pingCheck('database'),
// 메모리 사용량 체크
() => this.memory.checkHeap('memory_heap', 300 * 1024 * 1024),
// 디스크 사용량 체크
() => this.disk.checkStorage('storage', {
thresholdPercent: 0.9,
path: '/'
}),
]);
}
}
🧐 Indicator가 뭔데, 제 db를 찾죠? 어떻게?
우리가 AppModule에 등록한 모듈들을 이용해 찾습니다. 즉, NestJS의 의존성 주입 시스템을 이용합니다.
TypeOrmHealthIndicator를 예로 들면, 아래와 같은 흐름으로 찾을 수 있습니다.
memory, disk는 terminus에서 제공하는 모니터링 인디케이터로 Node.js의 process.memoryUsage() API를 사용하여 현재 프로세스의 메모리 사용량을 확인하고, Node.js의 fs 모듈과 diskusage 라이브러리를 사용하여 디스크 공간을 확인합니다.
헬스체크 주의사항: 자주 하는 실수들
헬스체크와 관련하여 쉽게 행해질 수 있는 실수들을 적어보았습니다.
- 과도한 체크
{ "healthCheck": { "interval": 5, // 너무 빈번한 체크 "timeout": 5, "retries": 3 } }- 짧은 주기의 헬스체크는 서버에 불필요한 부하를 줄 수 있습니다.
- ECS의 경우 대부분 30초 주기로도 충분하다고 합니다.
- 짧은 주기의 헬스체크는 서버에 불필요한 부하를 줄 수 있습니다.
- 부적절한 의존성 체크
@Get('health') async healthCheck() { try { // 외부 API 호출 await this.httpService.get('https://api.external.com/status').toPromise(); // Redis 체크 await this.redisService.ping(); // DB 쿼리 await this.repository.count(); return { status: 'ok' }; } catch (e) { throw new ServiceUnavailableException(); } }- 헬스체크에 너무 많은 외부 의존성을 포함하면, 단일 서비스 장애가 전체 헬스체크의 실패로 이어질 수 있습니다.
- 불충분한 예외 처리
@Get('health') async healthCheck() { try { await this.dbService.query('SELECT 1'); return { status: 'ok' }; } catch (e) { // 어떤 에러인지 구분하지 않고 모두 500 에러로 처리 throw new InternalServerErrorException(); } }- 에러의 종류와 원인을 구분하지 않는다면, 문제 해결을 위한 정보가 부족하게 될 거예요.
추천하는 헬스체크 패턴
- 계층적 헬스체크
Kubernetes와 유사하게 ECS에서도 두 가지 상태를 구분 관리하는 것이 좋습니다.// 상세한 헬스체크를 위한 DTO class HealthCheckResponse { @ApiProperty() status: 'ok' | 'error'; @ApiProperty() details: { database?: boolean; cache?: boolean; disk?: boolean; }; @ApiProperty() metrics?: { memory: number; cpu: number; }; } @Controller('health') export class HealthController { @Get('liveness') async liveness() { // 최소한의 체크만 수행 return { status: 'ok' }; } @Get('readiness') @HealthCheck() async readiness() { // 서비스 의존성 체크 return this.health.check([ () => this.db.pingCheck('database'), () => this.redis.checkHealth('cache'), ]); } } - 우아한 종료(Graceful Shutdown)
우아한 종료(Graceful Shutdown)는 애플리케이션이나 서비스가 갑작스럽게 중단되는 것이 아니라, 정상적인 절차를 거쳐 안전하게 종료되는 과정을 말합니다.// main.ts async function bootstrap() { const app = await NestFactory.create(AppModule); // SIGTERM 시그널 핸들링 process.on('SIGTERM', async () => { console.log('Received SIGTERM signal'); // 1. 헬스체크 실패 응답 시작 app.get(HealthService).setUnhealthy(); // 2. 일정 시간 대기 (ALB가 감지하고 트래픽 제외하도록) await new Promise(r => setTimeout(r, 10000)); // 3. 새로운 요청 거부 시작 app.get(HttpServer).close(); // 4. 진행 중인 요청 완료 대기 await app.get(RequestTracker).waitForRequests(); // 5. 애플리케이션 종료 await app.close(); process.exit(0); }); await app.listen(3000); } - ECS Task Definition 최적화
- startPeriod로 초기 구동 시간을 충분히 확보합니다.
- startPeriod는 컨테이너가 처음 시작된 후 헬스체크 성공 여부를 평가하기 전에 대기하는 시간이에요.
- 이 기간 동안 헬스체크는 실행되지만, 실패해도 재시도 횟수에 포함되지 않습니다.
- 애플리케이션이 완전히 초기화될 때까지 충분한 시간을 제공해 다음과 같은 상황에 유용합니다.
- 데이터베이스 연결, 캐시 워밍업, 설정 파일 로드 등 시간이 필요한 초기화 작업이 있는 애플리케이션
- 무거운 프레임워크나 런타임을 사용하는 애플리케이션
- 대용량 데이터를 메모리에 로드해야 하는 서비스
- startPeriod로 초기 구동 시간을 충분히 확보합니다.
- stopTimeout으로 우아한 종료 시간을 보장합니다.
- stopTimeout은 컨테이너에 SIGTERM 신호가 전송된 후 SIGKILL 신호를 보내기 전에 대기하는 시간이에요.
- 진행 중인 작업을 완료하고, 연결을 정상적으로 종료하고, 리소스를 정리할 시간 제공해야 합니다.
- 다음과 같은 상황에 유용합니다.
- 활성 트랜잭션이나 요청을 처리해야 하는 웹 서버
- 메시지 큐에서 작업을 처리하는 워커
- 데이터베이스 연결 풀을 정상적으로 닫아야 하는 애플리케이션
- 임시 파일이나 리소스를 정리해야 하는 서비스
{ "containerDefinitions": [{ "healthCheck": { "command": [ "CMD-SHELL", "curl -f http://localhost:3000/health/liveness || exit 1" ], "interval": 30, "timeout": 5, "retries": 3, "startPeriod": 60 }, "portMappings": [{ "containerPort": 3000, "protocol": "tcp" }], "stopTimeout": 120, "essential": true }] }
마치며
헬스체크는 ‘무엇을 확인하고자 하는가’를 명확히 하는 것이 가장 중요하다고 합니다.
각 계층의 특성을 이해하고 목적에 맞는 모니터링 전략을 수립한다면, 보다 안정적인 서비스 운영이 가능할 것입니다.
클라우드 환경에서 Layer 3,4에서의 헬스체크는 모르고 넘어갈 순 있지만, 우리가 하지 않을뿐 여전히 유효하다는 것이 이 글을 쓰며 내리게 된 결론입니다.
여기까지. 안녕!